
はじめに
Alexaスキルから、ユーザーの名前をつけて応答する方法について紹介します。
スキルから「○○さん、…」のように名前で呼びかけることで、ユーザーフレンドリな対話を実現でき、パーソナライゼーションによるUX(User eXperience)の向上に寄与できます。
やりたいこと
スキルが起動されると名前をつけて応答します。ただし毎回名前を呼ぶわけではなく、マルチターンの対話であれば、初回の応答時にのみ名前を呼ぶようにします。
これには、対話モデルでダイアローグが定義されていて、スロットの穴埋めや発話内容の確認のために、Alexaとユーザーの間で会話がやり取りされる場合も含みます。
ユーザー名の取得方法
音声プロフィールの登録
前提条件として、ユーザーが音声プロフィールを登録している必要があります。これはAlexaアプリから行います。登録方法については多くの解説がありますから、ここでは詳細は割愛します。
下記はAmazonサイトにある説明です。
- Alexaアプリを開きます
 。
。 - その他
 から設定を選択します。
から設定を選択します。 - マイプロフィールを選択します。
- 音声の横にある 作成を選択します。
- 続行を選択します。
パーソナライズの有効化
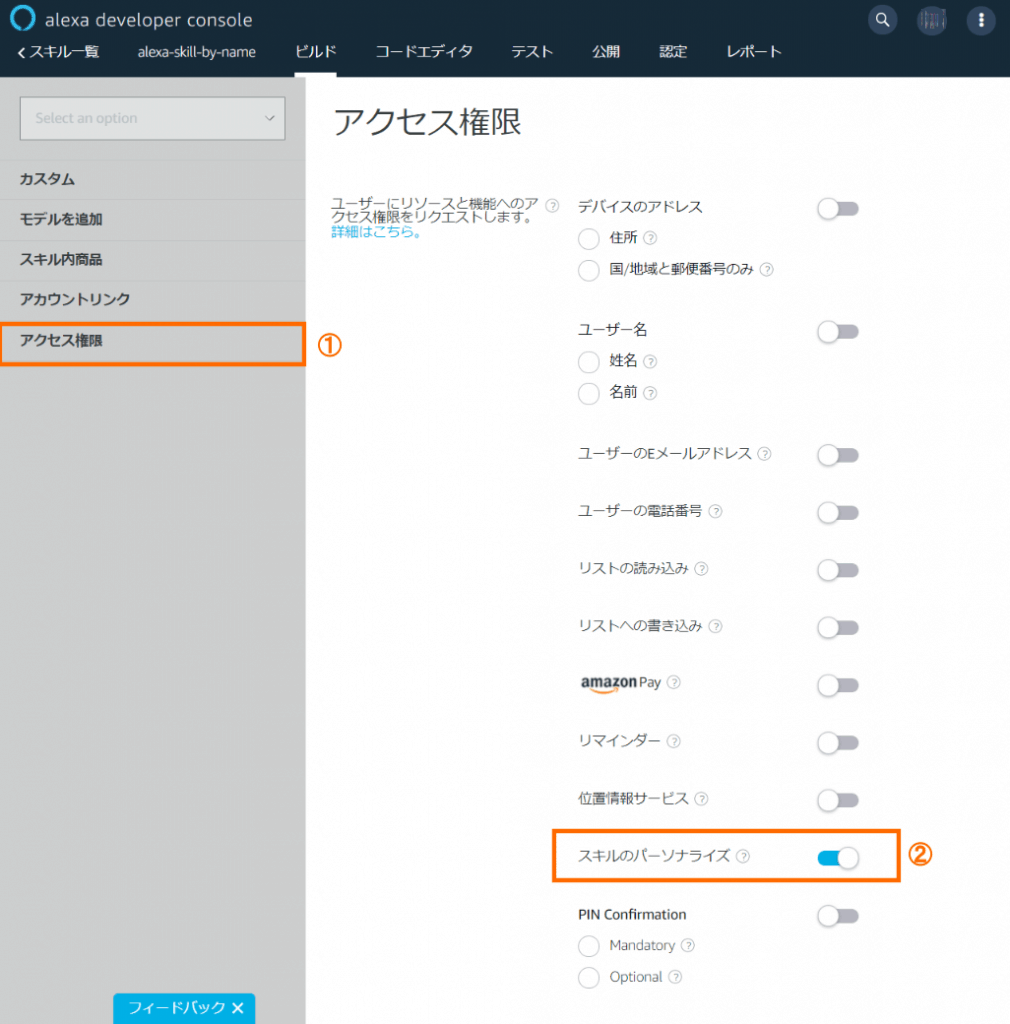
スキルからユーザー名を取得するには、開発者コンソールのアクセス権限の設定で、スキルのパーソナライズを有効にします。
ビルドタブで①モデルをクリックします。
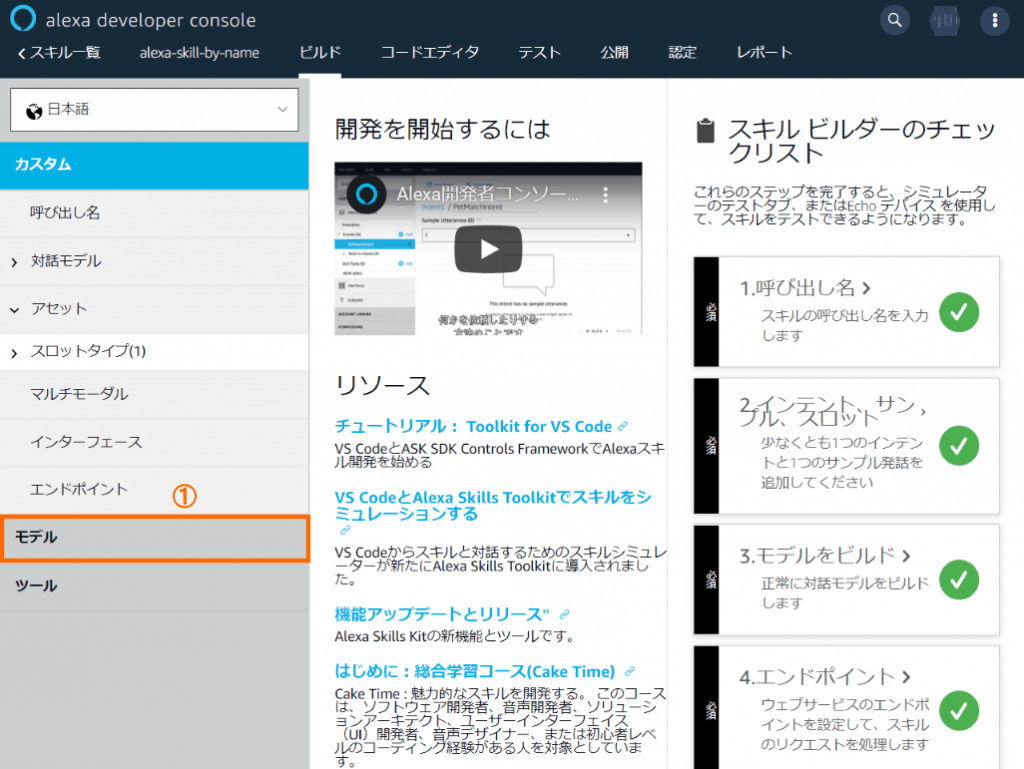
切り替わった画面で、①アクセス権限を選び、②スキルのパーソナライズをオンにします。
パーソンID(personId)の取得
スキルのコードの中で、話者を特定するために、パーソンID(personId)を取得します。スキルのパーソナライズが有効になると、スキルのリクエストの中に、パーソンIDが埋め込まれて送られてきます。これを取得します。
const personId = handlerInput.requestEnvelope.context.System.person?.personId;パーソナライズが有効になっていない場合は、パーソンIDは送られてきません。この場合は、名前を付けての応答はできません。
ユーザー名の取得
スキルからは、ユーザー名を直接取得することはできません。その代わりに、スキルからAlexaサーバーに返すレスポンスの発話テキストの中に、パーソンIDを含むタグを埋め込むことで、Alexaからの発話にユーザー名を含めることができます。タグを解釈してユーザー名に変換するのは、Alexaサーバー側の処理になります。
発話テキストに、下記のようなタグを埋め込むと、ユーザーの名前に変換されます。
<alexa:name type="first" personId="${personId}"/>初回呼び出しの判定
セッションの最初の呼び出しかどうかを判定するには、リクエストに埋め込まれてくる、その名もズバリnewというフラグを確認します。
if (request.session?.new) {
// 初回呼び出し時の処理 ...
}なおask-sdk-coreモジュールには、isNewSession(requestEnvelope)という、ヘルパー関数が提供されているので、実際のコードの中ではそちらを使います。
パーソンIDについての注意点
パーソンIDについては、技術ドキュメントには下記のように書かれています。
personId値は話者ごとに異なります。さらに、そのユーザーがパーソナライズの権限を与えているスキルごとに異なるpersonId値が割り当てられます。また、話者が2台のデバイスで同じスキルを使用する場合、スキルと話者は同じでも、それらのデバイスにはそれぞれ異なるpersonId値が割り当てられます。異なるスキル、アカウント、デバイス間ではpersonId情報が共有されません。

この通りであれば、複数のデバイスを使っている環境では、同じ話者でも異なるパーソンIDを持つことになります。これは話者ごとにデータを保管するようなスキルにとっては問題です。異なるデバイスからアクセスされた時には、同じユーザーとして識別できないからです。
※筆者の所有する数台のデバイスで試した限りでは同じpersonIdが得られます …
ただしユーザー名を付けて応答するだけであれば、これは問題になりません。パーソンIDが異なっていても、Alexaサーバー側で正しい名前に変換してくれるからです。
ユーザー名の埋め込み方法
スキルからパーソンIDとユーザー名を取得する方法を説明しました。次に得られたユーザー名をスキルからのレスポンスに組み込みます。これには下記の2つの処理が必要になります。
ResponseInterceptorでのユーザー名の埋め込み- オートデリゲートの無効化
それぞれについて以下で説明します。
ResponseInterceptorでのユーザー名の埋め込み
スキルでは、インテントに対応したハンドラが、呼び出されます。ResponseInterceptorは、そのハンドラの処理の後に呼び出され、ハンドラからのレスポンスをインターセプト (横取り) して、何らかの処理を追加できるようになっています。このResponseInterceptorで、初回のみユーザー名を埋め込めむようにします。
ResponseInterceptorのコードを下記に示します。
import * as Alexa from 'ask-sdk-core';
import * as Model from 'ask-sdk-model';
const ResponseInterceptor: Alexa.ResponseInterceptor = {
process(handlerInput, response) {
console.log('>> ResponseIntercepter ...')
const sessionAttributes = handlerInput.attributesManager.getSessionAttributes();
if (Alexa.isNewSession(handlerInput.requestEnvelope)) {
const personId =
handlerInput.requestEnvelope.context.System.person?.personId;
switch (Alexa.getRequestType(handlerInput.requestEnvelope)) {
case 'LaunchRequest':
case 'IntentRequest':
embedPersonName(response, personId);
break;
default:
}
}
}
}
function embedPersonName(response: Model.Response | undefined, personId: string | undefined): void {
if (response && isSsmlText(response.outputSpeech)) {
console.log('>> Adding person name');
let text = response.outputSpeech.ssml;
text = text.replace('<speak>', '').replace('</speak>', '');
text = `<speak>${getPersonName(personId)}、${text}</speak>`;
response.outputSpeech.ssml = text;
}
}
function isSsmlText(outputSpeech: any): outputSpeech is Model.ui.SsmlOutputSpeech {
return outputSpeech != null &&
typeof outputSpeech === 'object' &&
typeof outputSpeech.ssml === 'string';
}
function getPersonName(personId: string | undefined) {
if (personId) {
return `<alexa:name type="first" personId="${personId}"/>さん`;
}
return '';
}初回の呼び出しかどうかをチェックし、初回の呼び出しであれば、リクエストからpersonIdを取り出して、発話テキストの中にタグとして埋め込んでいます。
発話テキストには、2種類あります。Speech Synthesis Markup Language (SSML) とPlain Text(単純テキスト)です。ユーザー名のタグを埋め込めるのは、SSMLの場合のみです。単純テキストの場合は、埋め込むことはできません。発話テキストのタイプをチェックして、SSMLの場合のみユーザー名のタグを埋め込んでいます。
ただしテストした範囲ではPlain Textによる発話テキストを受け取ることはありませんでした。発話テキストはSDKの中で生成されています。技術ドキュメントには、SDKによるSSML, Plain Textの選択についての記述は見つかりませんでした。SDKに任せる場合は常にSSMLなのかも知れません。
オートデリゲートの無効化
対話モデルにスロットを含むダイアローグが定義されていて、かつオートデリゲートがオンになっている場合は、オートデリゲートをオフにする必要があります。
オートデリゲートがオンの場合、スロットを埋めるためのユーザーとの会話は、Alexaによって行われます。そしてスロットが埋められたあとに、スキルのハンドラが呼び出されます。この場合、ユーザーへの最初の発話はAlexaが行うためResponseInterceptorが呼び出されることはありません。従って最初の会話にユーザー名を加えることができません。
オートデリゲートをオフにすると、スロットを埋めるための会話は、スキルが自身で行うことになります。これによりResponseInterceptorが常に呼び出され、名前を追加できるようになります。
ただこのままだと、スロットを埋めるためのユーザーとの会話をAlexaに任せられるという、オートデリゲートの利点が失われてしまいます。この対策としてDialogDelegateHandlerを追加し、その中でもう一度同じインテントに対して、デリゲートをし直すということをしています。これによって、対話モデルに定義されたステップに従って、Alexaがユーザーと対話してくれます。
もし実際にダイアローグに介入して、ダイアローグの流れをコントロールしたい場合は、自前のダイアローグデリゲートハンドラを作成して、このDialogDelegateHandlerよりも前に呼び出されるようにしてください。(SkillBuildersでhandlerを作成する時に、DialogDelegateHandlerよりも前に登録します)
DialogDelegateHandlerのコードを下記に示します。
const DialogDelegateHandler: Alexa.RequestHandler = {
canHandle(handlerInput) {
let result = false;
const envelope = handlerInput.requestEnvelope;
if (Alexa.getRequestType(envelope) === 'IntentRequest') {
const dialogState = Alexa.getDialogState(envelope);
if (dialogState === 'STARTED' || dialogState === 'IN_PROGRESS') {
result = true;
}
}
return result;
},
handle(handlerInput) {
console.log('>> DialogDelegate ...')
const request = Alexa.getRequest<Model.IntentRequest>(handlerInput.requestEnvelope);
return handlerInput.responseBuilder
.speak('')
.addDelegateDirective(request.intent)
.getResponse();
}
}サンプルスキル
ResponseInterceptorとDialogDelegateHandlerを使ったスキルの例を、サンプルスキルとして紹介します。下記のレポジトリにスキルのプロジェクト全体を載せました。
サンプルスキルのユースケース
サンプルスキルのユースケースです。ドリンクメーカーという呼び出し名にしています。それぞれスキルに対する特定の呼び出し形式に対応しています。(以下、U – ユーザー、A – Alexa)
UC: #1
LaunchRequestが呼ばれる例
U: アレクサ、ドリンクメーカーを開いて
A: ○○さん、何かお飲みになりますか?
U: コーヒーが飲みたい
A: コーヒーですね、承知しました。
UC: #2
ダイアローグなしのIntentが直接呼ばれる例
U: アレクサ、ドリンクメーカーを開いて、メニューを教えて
A: ○○さん、コーヒー、紅茶、日本茶がご用意できます。どれをお飲みになりますか?
U: コーヒーが飲みたい
A: コーヒーですね、承知しました。
UC: #3
ダイアローグの途中でスロットの穴埋めがある例
U: アレクサ、ドリンクメーカーを開いて、飲み物を注文して
A: ○○さん、コーヒー、紅茶、日本茶がご用意できます。どれをお飲みになりますか?
U: コーヒーが飲みたい
A: コーヒーですね、承知しました。
UC: #4
ダイアローグのスロットが最初から埋まっている例
U: アレクサ、ドリンクメーカーを開いて、コーヒーを注文して
A: ○○さん、コーヒーですね、承知しました。
サンプルスキルの処理の流れ
下図にサンプルスキルにおける処理の流れを示します。
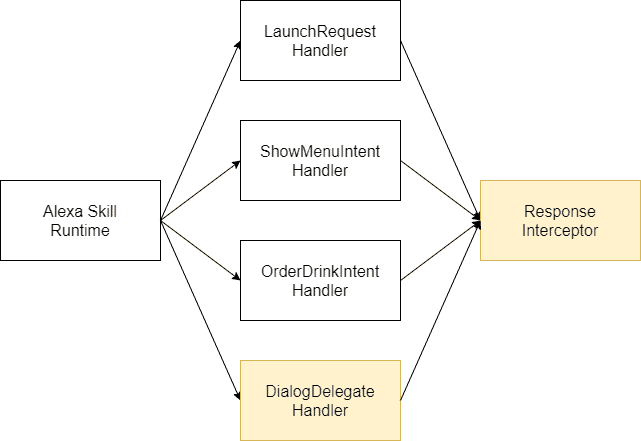
Alexa Skill Runtimeから、スキルの各ハンドラが呼び出されます。ここは開発者からは直接見えない部分です。
LaunchRequestHandler, ShowMenuIntentHandler, OrderDrinkIntentHandlerは、それぞれユーザーからのリクエストに応答します。
DialogDelegateHandlerは、ダイアローグの処理の中で呼び出されます。
ResponseInterceptorは、スキルのハンドラが呼び出されたあとに呼び出されます。
対話モデルの定義
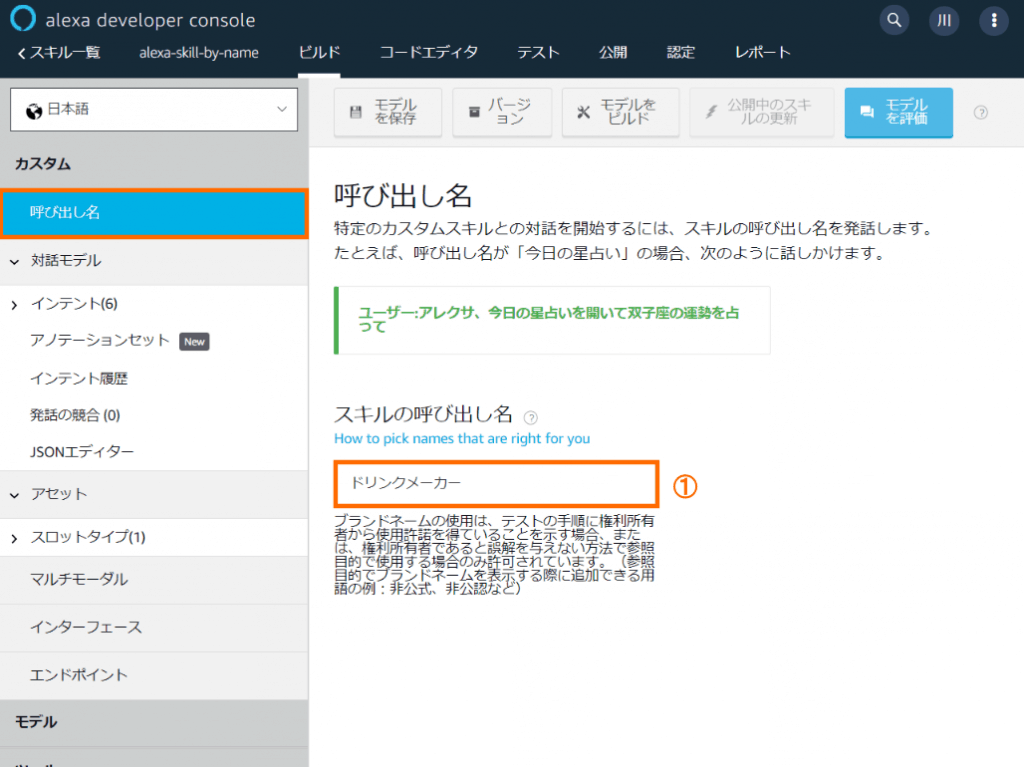
呼び出し名の設定
呼び出し名に①ドリンクメーカーを設定します。
スロットタイプの追加
【スロットタイプ】に①DrinkTypeを追加します。
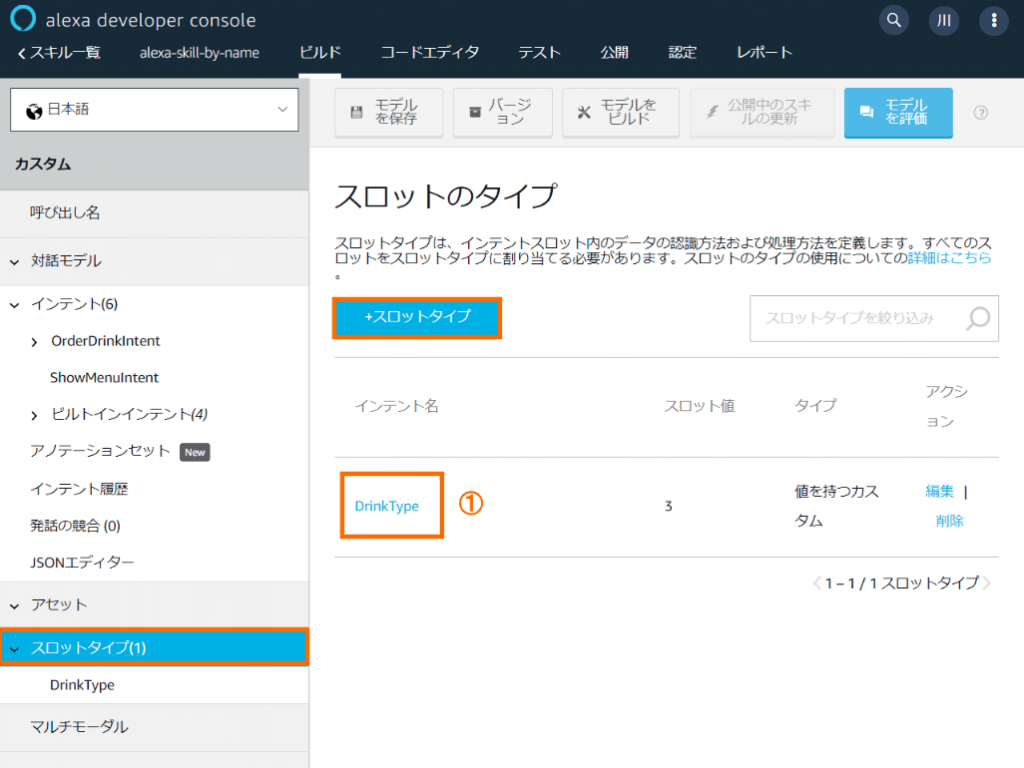
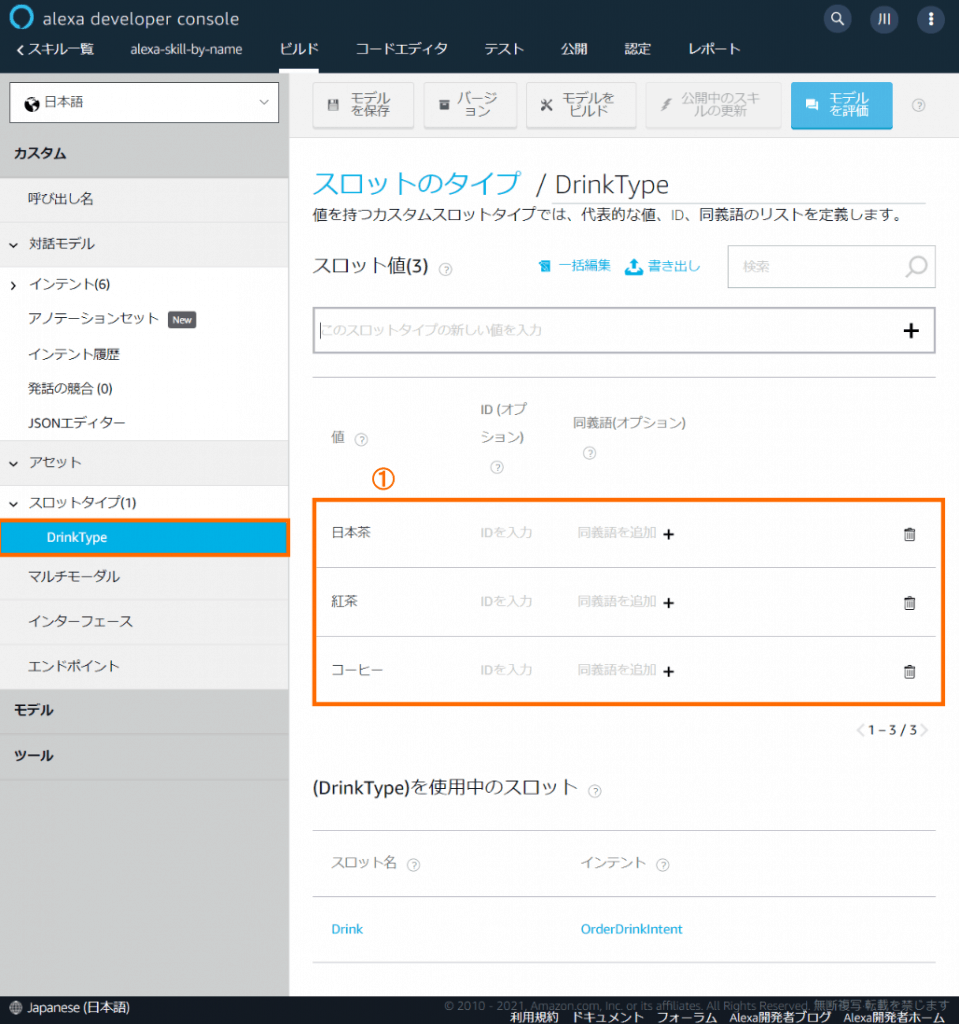
DrinkTypeの【スロット値】に①の値(日本茶、紅茶、コーヒー)を追加します。
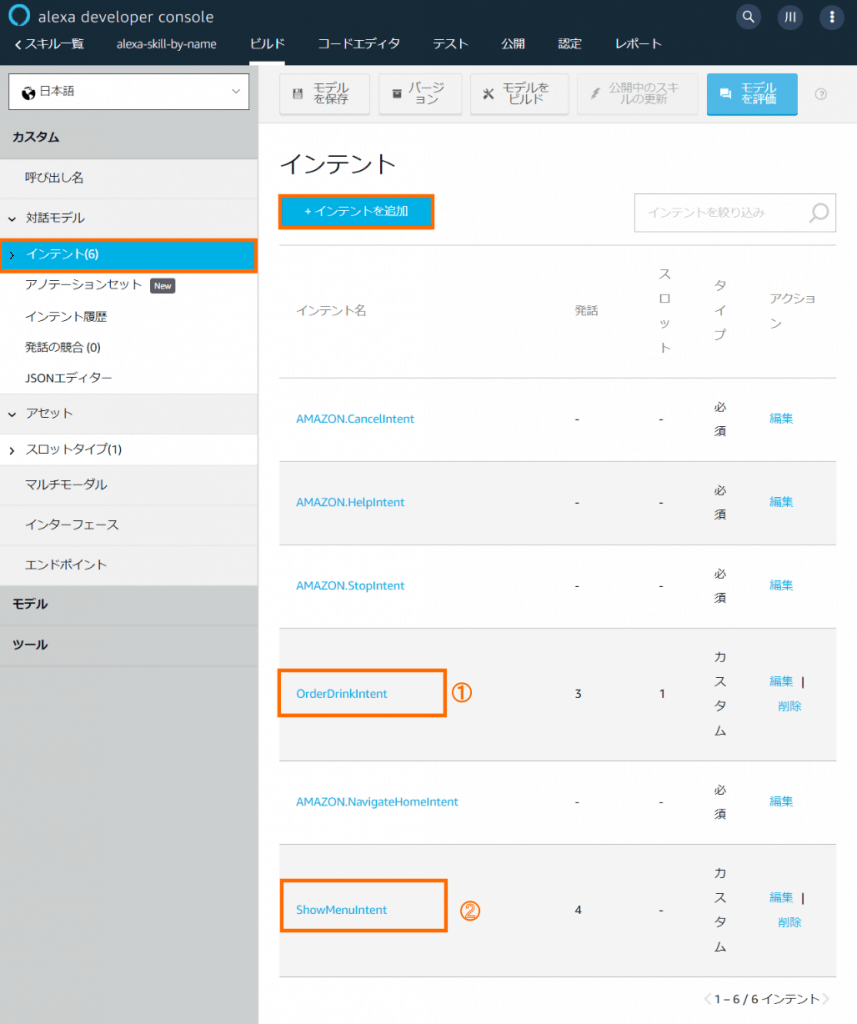
インテントの追加
【インテント】に①OrderDrinkIntent, ②ShowMenuIntentを追加します。
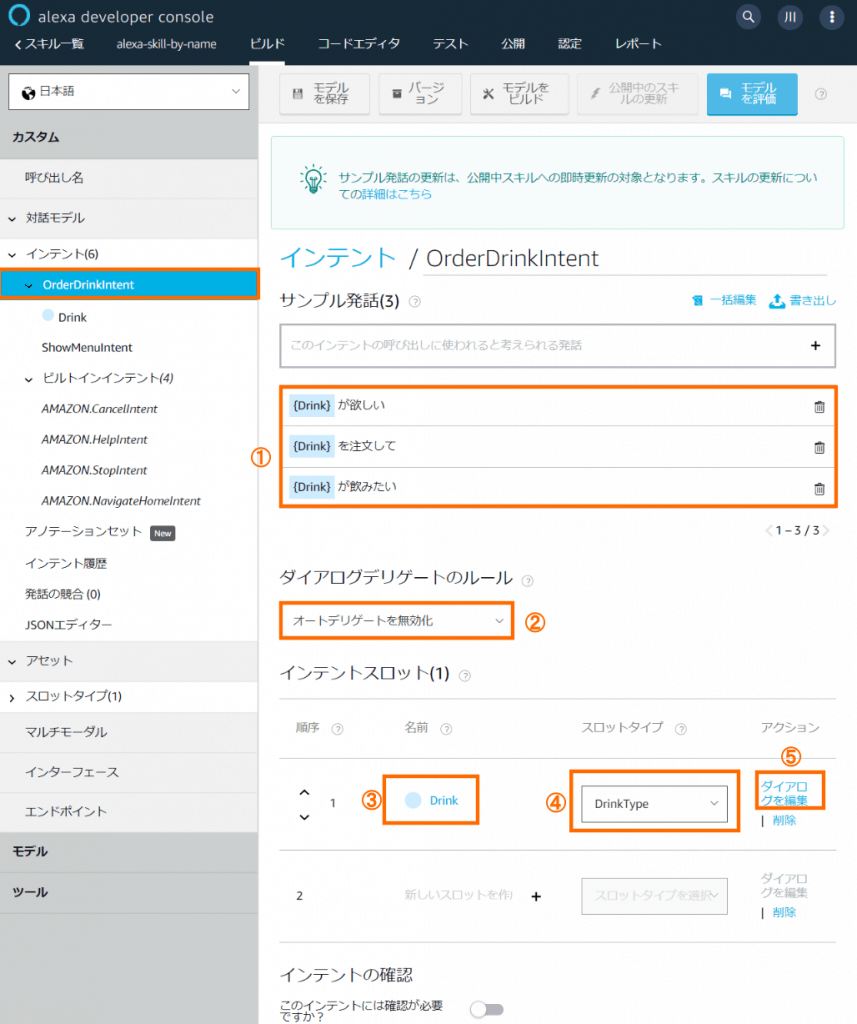
OrderDrinkIntentの定義
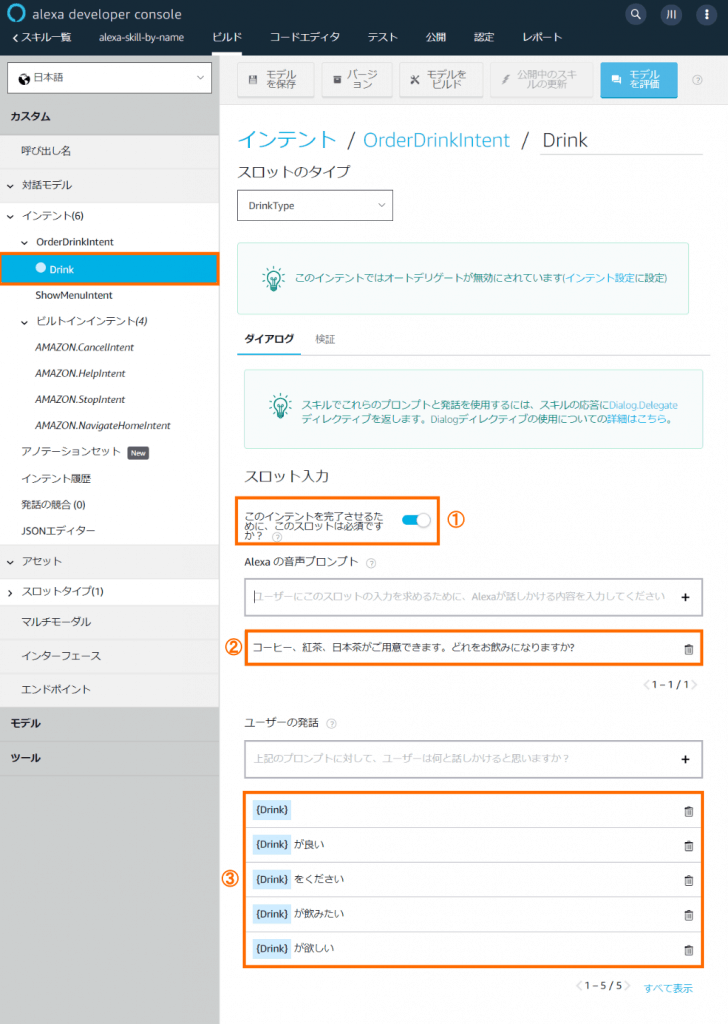
【サンプル発話】に①の発話例を追加します。【ダイアログデリゲートのルール】で②オートデリゲートを無効化を選びます。【インテントスロット】に③Drinkを追加し、【スロットタイプ】は④DrinkTypeとします。⑤ダイアログの編集に進みます。
スロットDrinkに対するダイアローグを定義します。【スロット入力】で①このインテントを完了させるために、このスロットは必須ですか?をオンにします。【Alexaの音声プロンプト】に②を追加します。【ユーザーの発話】に③を追加します。
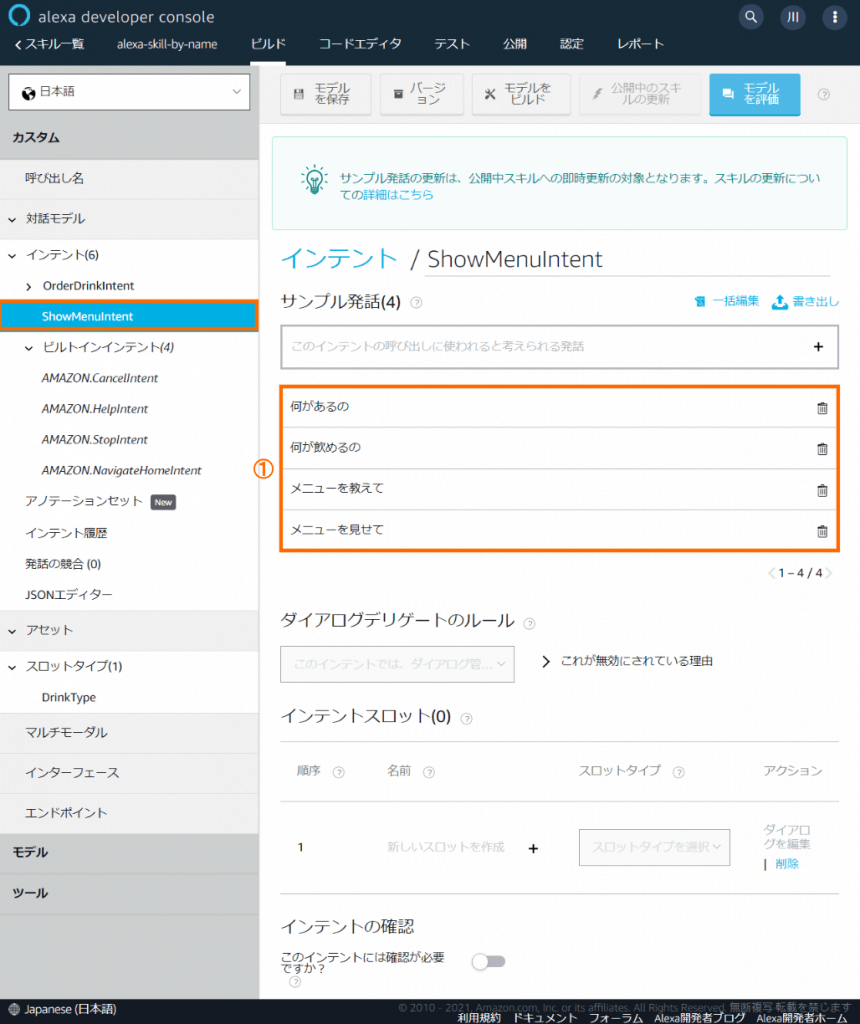
ShowMenuIntentの定義
【サンプル発話】に①の発話例を追加します。
動作確認
スキル全体をAlexa-Hostedスキルとしてレポジトリからインポートしてください。
実機 (Echoデバイス) または開発者コンソールのテスト画面から、ユースケースに載せた対話を実施してください。各対話の最初にユーザー名が呼ばれるのが確認できます。
おまけ
今回のユースケースでは、初回の呼び出し時のみ、名前を付けて応答するようにしました。しかし、途中の呼び出しでも、名前を付けたい場合があるかも知れません。その場合は、初回の呼び出し時にパーソンIDをセッションアトリビュートに保存しておき、それを後続の呼び出しでも使うようにします。
実はパーソンIDは、スキルの呼び出しの度に、リクエストに埋め込まれているので、2回目以降の呼び出しでも、そこから取ることは可能です。しかしそれはお勧めできません。
マルチターンの会話の場合、「○○でよろしいでしょうか?」といった形でスキルから問いかけて、ユーザーから「はい」「いいえ」のような短い答えを受け取る場合があります。このようなとき、Alexaは話者を上手く認識できない場合があるようです。通常、発話が長いほど認識精度は上がると考えられます。最初の発話が一番長いため、一番良い精度が期待できます。
(2023/04/24 – いつの間にかAlexaアプリで読みを登録できるようになっていました)パーソンIDに紐付いている名前は、正確に読まれないケースがあるようです。実際、筆者の名前も微妙に違っています。これは名前がAmazonアカウントに登録されている、漢字名を参照しているからだそうです。読みがなを登録していても、無視されます。解決策は、漢字名のところにひらがなで登録することだそうです。
おわりに
カスタムスキルからの応答テキストに、ユーザーの名前を付けて呼びかける方法を紹介しました。パーソナライズはUXの向上に重要ですし、ユーザーの名前を呼ぶのはその第一歩と言えます。ただあくまでも第一歩であり、ユーザーの好みに合わせたサービスの提供など、色々と工夫の余地がありそうです。ただし本文でも書いたように、デバイスごとに異なるパーソンIDが返ってくるとなると、制約が大きいです。何か良い方法がないものか思案中です。
付録. ソースコード
変更履歴
| 日付 | 内容 |
|---|---|
| 2023/04/24 | 読みの登録ができるようになったことを追記 |
| 2021/10/15 | 説明の構成を見直し |
| 2021/06/04 | タイポの修正 & コードのリファクタリング結果を反映 |
| 2021/05/03 | 初版公開 |

